Please read the instructions.
Michael Vanikiotis
Project Overview:
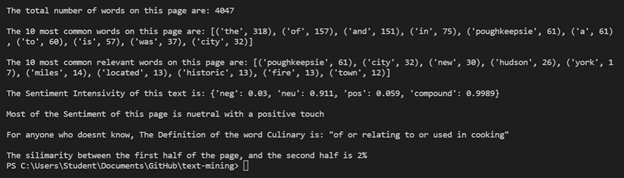
The data I used was sourced from the “Poughkeepsie, New York” Wikipedia page (This is the City I am from in New York). I also used some data from the subReddit: “NatureIsFuckingLit” as well. In short, I read in the data from my sources and did some basic word/headline analysis first. After this, I used some AI libraries to go deeper into my data. I came into the project hoping to better learn how to use an API and supporting libraries. In the process, I also got to learn some pretty cool and useful libraries.
Implementation:
After reading in my Wikipedia data, I began my basic word analysis. This consisted of formatting the data correctly. After standardizing the Wikipedia page, I found the total number of words on the page. I then found the 10 most common words in the page. But, after doing so, I realized that most of the top 10 words on the page were “filler words”. These words are pretty much irrelevant to me. So, I used the nltk. I used this libraries’ “stopwords” capabilities to restructure the data and remove all of the irrelevant words (and, is, the, etc…). After this, it wasn’t perfect, and I still had to do some more cleaning for the common symbols that were used (“=”, “==”,”===”, “(“, etc…)
When I finished cleaning all the data, I found the 10 most common relevant words on the page. This was a much more relevant list of words. I then moved on to deeper analysis. I again used the nltk library and used SentimentIntensityAnalyzer. I used this to score the Sentiment of the whole Poughkeepsie Wikipedia page. After this, I found the definition of the word culinary. Lastly, I analyzed the relationship similarity between the first half of the page to the last half of the page. At this point I had the choice to allow the order of the words in the string matter. But, I didn’t want the long strings to have low scores because of order. I just wanted to see how similar the two sections of the text were. So, I decided not to allow the order of the words to effect the score.
Results:
After removing the irrelevant words from the text, I found the 10 most common important words. Two of the surprising results of this are: new and historic. Interestingly these are very contradictory words. The word “new” shows up 30 times throughout the text. The word “historic” shows up 13 times. This is interesting, because it does explain the dynamic of the city. It is a city that is known for having its history, but especially recently, there has been a good amount of newness to it.
From the sentiment analysis, it was found that the sentiment of the piece was mostly neutral with a positive connotation. This will prove is that the piece was not written in a very bias manner, which is a good thing if we are using this site for non-bias information about the City of Poughkeepsie. I was also able to use nltk to find the definition of the word culinary to be “of or relating to or used in cooking”. When I looked at the unordered similarity score of the beginning of the Wikipedia page compared to the end of the Wikipedia page it was found that the is only a 2% relationship between the two. This was surprisingly low to me as I would have assumed that more of the text would relate to each other because the two components being compared are fragments of the same text.
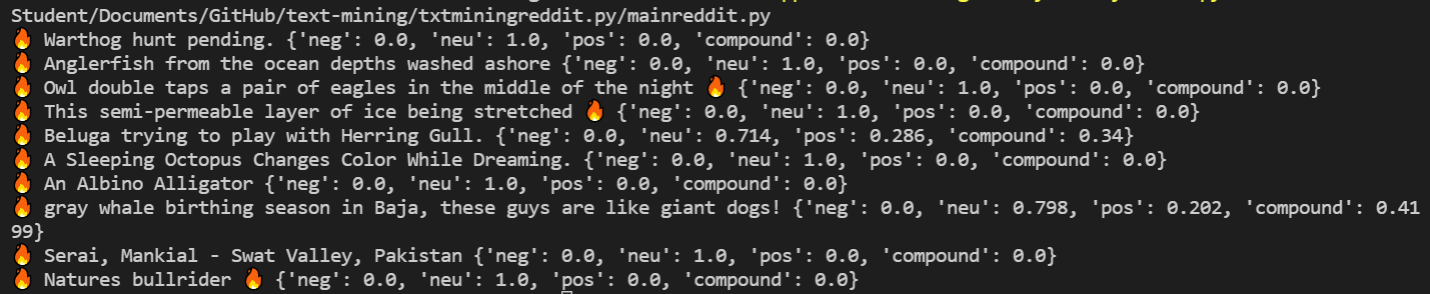
Here is some information that I pulled off of the subReddit: “NatureIsFuckingLit”
Reflection:
I learned the real meaning of a library and how they are somewhat easy to find and use. Going online and finding the specific examples of how to use the libraries is very helpful. It opened my mind to the real capabilities of python. This showed me how learning a library will make python easier and more insightful with so much less work. I wish that my twitter API Code was not denied so that I could have used the twitter API. I probably learned the most cool and real useful elements of python during this project: API and Library Reading and Integration. Yes, I will be using this in the future. This is the excited stuff that I am happy I signed up for this class to learn.