
Elasticsearch+Scrapy 搭建一套集成爬虫以及入库到Elasticsearch的一套整合体搜索引擎
省略部分没用的结构
├─ArticleSpider
│ ├─images # 存储图片
│ │
│ ├─models # 生成Elasticsearch的表结构
│ │
│ ├─spiders # 爬虫主要逻辑
│ │
│ ├─tools # 常用工具、比如爬虫代理ip库,浏览器浏览器selenium爬取
│ │
│ ├─utils # 常用的算法等、比如MD5算url
│ │
├─chromdriver2.33 # 这些是使用浏览器selenium爬取时的一些常用chromdriver。window、macos、linux都有
├─chrome_nocdc # 这是我使用的chromdriver
├─cookies # 有时候要cookies.这里是存储cookies的地方
├─java # windows下 javase1.8,网上也不好找
├─resources # 常用资源
│ ├─elasticsearch-head-master # elasticsearch-head是elasticsearch的可视化,有点像navacat
│ │
│ ├─elasticsearch-rtf # elasticsearch-rtf是elasticsearch的中文版,集成了很多插件
│ │
│ ├─kibana-5.1.1-windows-x86 # 类似于restful 操作elasticsearch,这样我们就可以使用命令如GET、PUT等方法一样操作了
│ │
├─main.py # 爬虫启动程序
├─requirements.txt # 项目库
本环境是在python3.6下安装配置的,支持windows、macos、linux
因为我是在windows上操作的,下面我将介绍如何安装此项目并运行
1. git clone https://github.com/jusk9527/LcvSearch.git
2. 在该目录下创建一个虚拟环境
3. pip install -r requirements.txt -i https://pypi.douban.com/simple # 用豆瓣源下载比较快,不然等到天亮
## 启动elasticsearch-rtf
- 在elasticsearch-rtf的bin目录下执行命令 elasticsearch.bat
- 启动成功
- 打开浏览器http://127.0.0.1:9200/ 即可查看效果表示成功
- 其他问题可参考项目 https://github.com/medcl/elasticsearch-rtf
## 启动elasticsearch-head-master
- 这个你得有node环境,怎么安装node环境可以看你看网上具体教程
- 安装完了node环境在命令行中执行npm查看是否成功
- 由node环境执行 npm install -g cnpm --registry=https://registry.npm.taobao.org 安装ncpm 。由于国内下载太慢!还是用cnpm吧
- 在elasticsearch-head-master 下执行 cnpm install和cnpm run start
- 执行后打开浏览器http://127.0.0.1:9100/ 成功即可
- 如果出错可以删除我本地的包 即 node_modules 这个文件
- 其他问题可参考项目 https://github.com/mobz/elasticsearch-head
## 启动 kibana
- 在kibana-5.1.1-windows-x86 目录下的bin目录下执行命令 kibana.bat
- 执行成功后我们即可在浏览器中打开 http://127.0.0.1:5601/
- 我们在Dev Tool中即可写我们的对应搜索了
- 其他系统可下载别的系统对应的版本 https://www.elastic.co/cn/downloads/past-releases/kibana-5-1-1
## 数据库安装之类的
- 由于爬虫中使用了MongoDB和mysql,所以具体你的mysql数据库面之类的须在settings中修改
MYSQL_HOST = ""
MYSQL_DBNAME = "article_spider"
MYSQL_PORT =
MYSQL_USER = ""
MYSQL_PASSWORD = ""
- 注意mysql中创建数据库一定得是article_spider ,创建表是jobblole_article,表结构是如下这几个字段,不然会出错 | title | url | url_object_id | tags | content | create_date | front_image_path |
- mongodb呢?需要在pipelines.py中修改面啥的,非关系型数据库只需要修改即可,并不需要如关系型数据库先创建啥的,只需要修改这行连接就行 self.client = pymongo.MongoClient('mongodb://root:root@45.76.219.234:27017/')
- 首页效果
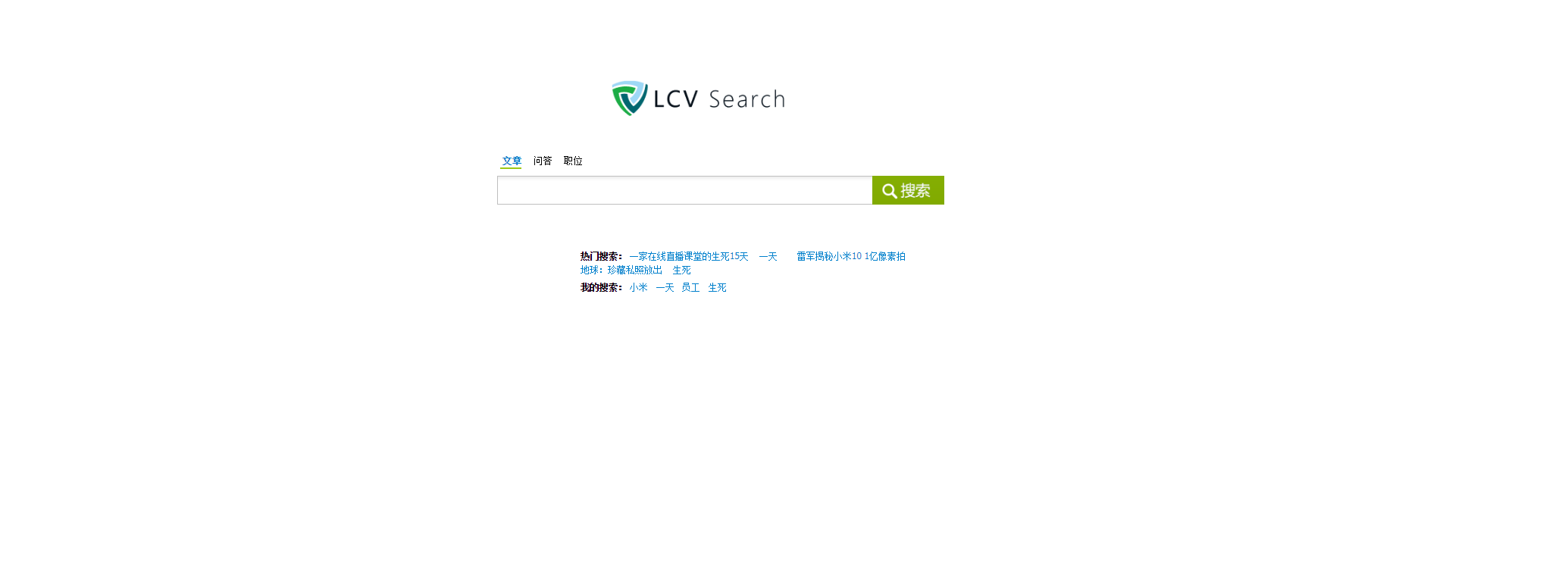
- 搜索结果

- 点击跳转详情页面

- 热词搜索排行
- 解决全部搜索排行问题
- 我的搜索记录
- 解决了忘词、历史记录问题
- 词条问题
- 搜索时间问题
- 分词问题
- 关键字高亮问题
- qq群 297599213
- 提 issue 请尽量到GitHub