![]()
Production-grade football analytics platform — 9.2M+ events, 3,464 matches, XGBoost xP (AUC 0.8948) + xG (AUC 0.7822, 88k calibrated predictions). Engineered for real-world constraints: OOM-safe server-side cursor writes, idempotent fault-tolerant restarts, and fully autonomous PDF/XML match reporting. Orchestrated end-to-end by Apache Airflow.
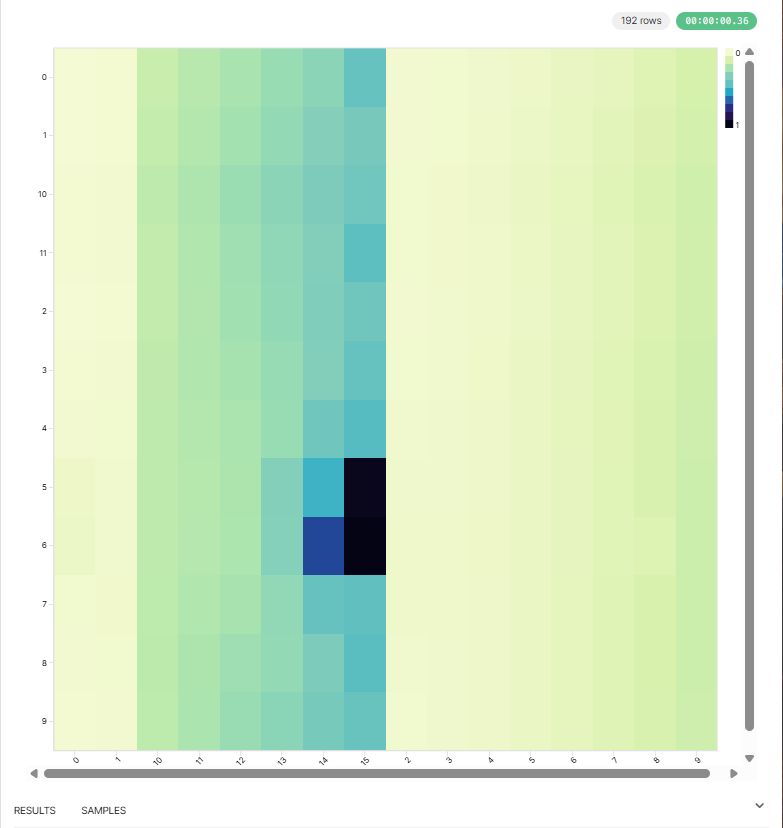
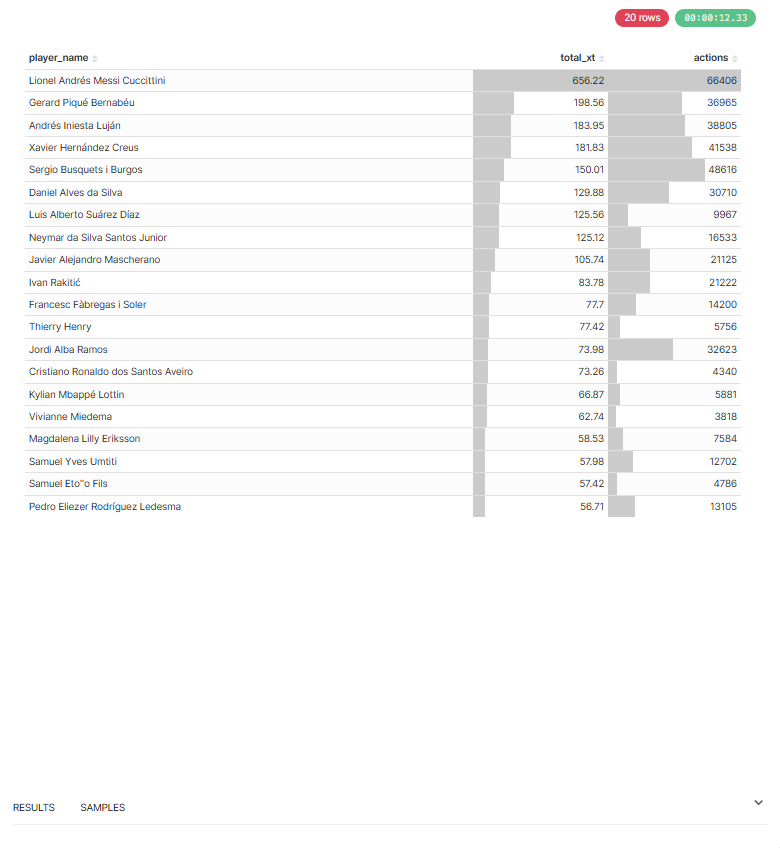
| xT Surface Heatmap | Player xT Ranking |
|---|---|
 |
 |
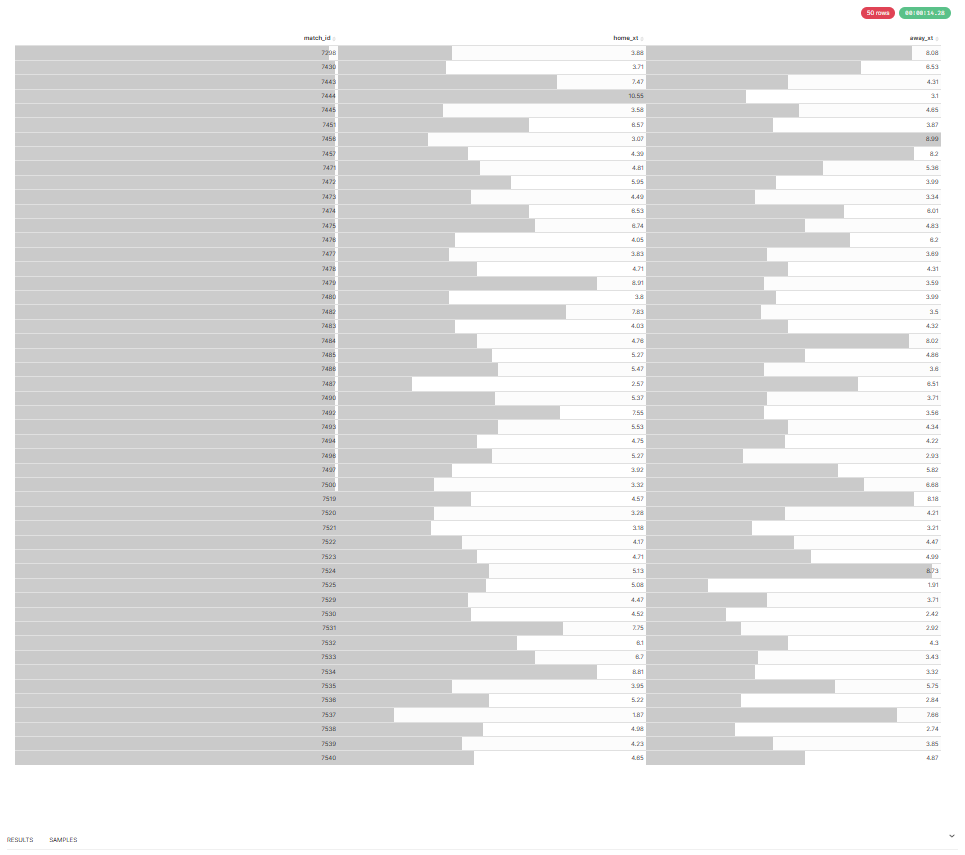
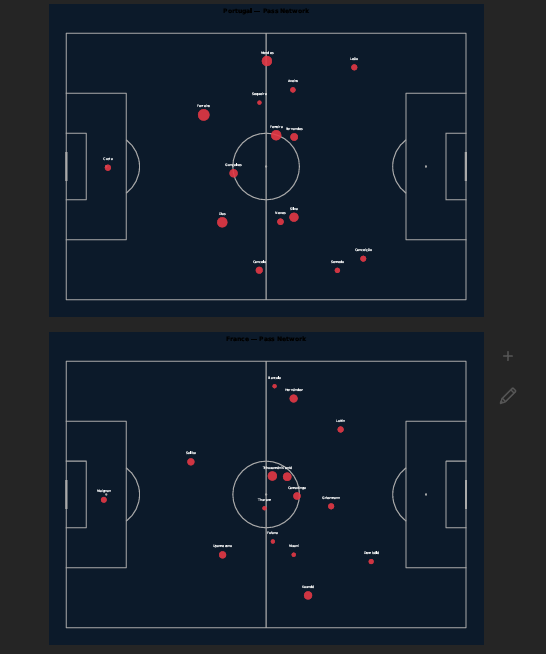
| Match xT Balance (Home vs Away) | PDF Match Report |
|---|---|
 |
 |
flowchart TD
SB[("StatsBomb\nOpen Data\n9.2M events / 3,464 matches")]
subgraph AIRFLOW["⚙️ Apache Airflow — 3 DAGs"]
direction TB
DAG1["ingestion_pipeline\n● daily 02:00 UTC\n● incremental, ~2.5 s/match"]
DAG2["ml_training\n● weekly Sun 03:00\n● xP + xG + K-Means in parallel"]
DAG3["matchday_push\n● manual trigger\n● PDF + XML generation"]
end
subgraph PG["🗄️ PostgreSQL 15"]
FACT["fact_events\n9.2M rows · 40+ LIST partitions\nxt_value · xp_value · xg_value columns"]
DIM["dim_matches · dim_players\ndim_teams · dim_competitions"]
AUX["xt_surface (192 cells)\nmodel_registry\nset_piece_clusters"]
end
subgraph DBT["📦 dbt 1.7"]
STG["3 staging models\nstg_events · stg_passes · stg_shots"]
MART["4 mart models\nplayer_metrics (total_xg · avg_xg · finishing_quality)\nteam_summary · match_summary\ncompetition_leaderboard (xt_per_match rank)"]
end
subgraph ML["🤖 ML Pipeline"]
XT["xT Model\nValue iteration · 16×12 grid\n5,375,085 rows written"]
XP["XGBoost xP\nAUC = 0.8948 · log-loss = 0.3236\n3,387,760 predictions"]
XG["XGBoost xG\nAUC = 0.7822 · calibrated avg=0.111\n88,023 shot predictions"]
KM["K-Means Clustering\n6 corner delivery zones · 6 shot zones\npress trigger detection"]
end
subgraph SERVE["📊 Serving Layer"]
SS["Apache Superset\n7 charts · Matchday Analytics dashboard"]
PDF["PDF Match Reports\nmplsoccer · 5-page per match"]
XML["SportsCode XML\n25 top-xT events · Hudl-compatible"]
GR["Grafana\npipeline & container monitoring"]
end
SB --> DAG1
DAG1 --> FACT & DIM
FACT --> DAG1
FACT --> DAG2
DAG2 --> XT & XP & XG & KM
XT & XP & XG & KM --> AUX
FACT & DIM --> STG --> MART
MART --> SS
FACT --> DAG3 --> PDF & XML
PG --> GR
xForge is not just a data pipeline; it is an operational engine designed to solve real-world football analytics bottlenecks:
- Data-Driven Scouting: Traditional completion rates are misleading. By filtering players who successfully complete high-difficulty (low xP) but high-reward (high xT) passes, scouting departments can identify undervalued, high-vision playmakers before their market value peaks.
- Tactical Opponent Analysis: Autonomous generation of Press Intensity and xT Surface Heatmaps allows coaching staffs to instantly identify opposition defensive vulnerabilities (e.g., high-threat leaks in specific half-spaces) without manual data slicing.
- Autonomous Video Analysis Integration: The pipeline automatically generates HUDL Sportscode-compatible XML files mapped to the top 25 highest-xT events of a match. This eliminates hours of manual video tagging for performance analysts, allowing them to focus strictly on tactical review.
- Striker Evaluation via Finishing Quality: The
finishing_qualitymetric (goals − total_xG) separates clinical finishers from shot-volume players. A striker with finishing_quality +189 (Messi, Barcelona) is systematically outperforming expected goals — exactly what recruitment departments need when evaluating transfer value beyond raw goal counts.
While the current architecture handles event data at scale, the next iterations of this project will focus on:
- Tracking Data Integration: Transitioning from an RDBMS to a Data Lake architecture to ingest and process 25 FPS X,Y coordinate tracking data.
- Real-time Streaming: Replacing batch Airflow ingestion with Apache Kafka to process match events in milliseconds, powering live in-match dashboards.
- MLOps Implementation: Integrating MLflow for continuous model registry, monitoring XGBoost performance over time, and automated retraining triggers to prevent model drift.
Training an XGBoost classifier on 3.4M pass events inside a 4 GB Codespace would OOM-kill. This pipeline solves it in two stages:
- Training: stratified random sample of 300k rows via
ORDER BY RANDOM() LIMIT 300_000— sufficient for AUC 0.8948. - Prediction: server-side
psycopg2named cursor streams rows in 50k-row chunks. Training data is explicitly freed withdel+gc.collect()before the prediction phase begins.
# server-side cursor — no full result set in RAM
cur = conn.cursor("xp_pred_cur")
cur.execute("SELECT ... FROM fact_events WHERE xp_value IS NULL")
while rows := cur.fetchmany(50_000):
probas = model.predict_proba(build_features(rows))
write_chunk(probas) # commit per chunkEvery prediction write filters WHERE xp_value IS NULL. If the container is killed mid-run, restarting resumes exactly where it stopped — no duplicates, no data loss. The postStartCommand in .devcontainer auto-triggers on Codespace restart; the run() entrypoint exits immediately if the model file exists and zero rows remain unpredicted.
fact_events is partitioned by competition_id using PostgreSQL LIST partitioning (40+ partitions). Query planners prune irrelevant partitions automatically — full-competition scans stay fast at 9.2M rows without manual sharding.
The matchday_push DAG generates a complete 5-page PDF and a SportsCode/Hudl-compatible XML file for any match_id without human intervention. Reports are written to a volume-mounted reports/ directory accessible from the host.
| Model | Algorithm | Target | Result |
|---|---|---|---|
| xT Surface | Value iteration (15×) | Threat per pitch cell | 192 cells, max=0.298 |
| xG Classifier | XGBoost | Goal probability per shot | AUC 0.7822, 88,023 predictions, post-hoc calibrated |
| xP Classifier | XGBoost | Pass completion probability | AUC 0.8948, log-loss 0.3236 |
| Corner Delivery Clustering | K-Means | Set-piece delivery zones | 6 clusters on corner origin coords |
| Shot Location Clustering | K-Means | Shot zone patterns | 6 clusters — correct StatsBomb zones (6-yard box: x>114, penalty area: x>102) |
| Press Trigger | Rule-based sequence | High-press moment detection | Ball recovery + 3 defensive actions / 5 s |
xG features: distance_to_goal, angle_to_goal, under_pressure, minute_bin — location-based coordinate model consistent with academic xG literature. Class imbalance (~10% goals) handled with dynamic scale_pos_weight. Raw XGBoost probabilities were post-hoc calibrated via multiplicative rescaling (xg_value × actual_goals / sum_predicted_xg) so that sum(xG) = 9,790 = actual goals, yielding avg_xg = 0.111 (11.1% goal rate) ✅
xP features: start_x/y, end_x/y, distance, angle_to_goal, under_pressure, minute_bin
finishing_quality = goals − total_xG per player. Positive = clinical finisher outperforming expectation; negative = poor conversion. Available in
mart_player_metrics. Example: Messi (Barcelona) = +189.6.
| DAG | Schedule | Tasks |
|---|---|---|
ingestion_pipeline |
Daily 02:00 UTC | ingest → dbt_run → dbt_test → xt_model → superset_init |
ml_training |
Weekly Sun 03:00 | tactical_models ‖ predictive_models ‖ xg_model → dbt_refresh_marts (all 3 ML tasks in parallel) |
matchday_push |
Manual trigger | ingest_match → generate_pdf → generate_xml → send_email |
| Metric | Value |
|---|---|
| Matches ingested | 3,464 |
| Total events | 9,200,000+ |
| DB partitions | 40+ (by competition) |
| xT records written | 5,375,085 |
| xP predictions written | 3,387,760 |
| xG predictions written | 88,023 (calibrated, avg_xg = 0.111) |
| Ingestion throughput | ~2.5 s / match |
| Write chunk size | 50,000 rows |
INFO Loading pass data for training (sample 300,000 rows)…
INFO Training XGBoost classifier…
INFO === xP Model Metrics ===
INFO AUC: 0.8948
INFO Log-loss: 0.3236
INFO Accuracy: 0.8221
INFO Model saved → /opt/airflow/models/xp_model.joblib
INFO Starting chunked prediction (server-side cursor, chunk=50,000)…
INFO Chunk 1/68 written 50,000 rows [total: 50,000 / 3,387,760]
INFO Chunk 2/68 written 50,000 rows [total: 100,000 / 3,387,760]
…
INFO Chunk 68/68 written 37,760 rows [total: 3,387,760 / 3,387,760]
INFO xP write complete — 3,387,760 predictions committed to fact_events.xp_value
INFO Training sample loaded: 80000 shots
INFO Class balance: 8885 goals / 71115 non-goals → scale_pos_weight=8.01
INFO === xG Model Metrics ===
INFO AUC: 0.7822
INFO Log-loss: 0.3541
INFO Accuracy: 0.8893
INFO xG model saved → /opt/airflow/reports/xg_model.joblib
INFO Training data freed. Starting prediction phase...
INFO xG written: 50000 rows committed
INFO xG written: 88023 rows committed
INFO xG write complete — 88023 shots updated
-- Post-hoc calibration (DB-level rescaling):
UPDATE fact_events
SET xg_value = ROUND((xg_value * 9790.0 / 35658.0)::numeric, 6)
WHERE event_type = 'Shot' AND xg_value IS NOT NULL;
-- UPDATE 88023
-- After: avg_xg = 0.1112 ✓ total_xg = 9790 = actual goals ✓
$ dbt run --select marts
Running with dbt=1.7.4
Concurrency: 1 threads (target='prod')
1 of 4 START sql table model analytics_marts.mart_player_metrics ........... [RUN]
1 of 4 OK created sql table model analytics_marts.mart_player_metrics ...... [SELECT 11778 in 4.83s]
2 of 4 START sql table model analytics_marts.mart_team_summary ............. [RUN]
2 of 4 OK created sql table model analytics_marts.mart_team_summary ........ [SELECT 337 in 3.21s]
3 of 4 START sql table model analytics_marts.mart_match_summary ............ [RUN]
3 of 4 OK created sql table model analytics_marts.mart_match_summary ....... [SELECT 3464 in 5.67s]
4 of 4 START sql table model analytics_marts.mart_competition_leaderboard .. [RUN]
4 of 4 OK created sql table model analytics_marts.mart_competition_leaderboard [SELECT 11367 in 2.94s]
Finished running 4 table models in 0 hours 0 minutes and 16.65 seconds (0:00:16).
Completed successfully
Done. PASS=4 WARN=0 ERROR=0 SKIP=0 TOTAL=4
SELECT
(SELECT COUNT(*) FROM fact_events WHERE xt_value IS NOT NULL) AS xt_rows,
(SELECT COUNT(*) FROM fact_events WHERE xp_value IS NOT NULL) AS xp_rows,
(SELECT COUNT(*) FROM fact_events WHERE xg_value IS NOT NULL) AS xg_rows,
(SELECT ROUND(AVG(xg_value)::numeric, 4)
FROM fact_events WHERE event_type = 'Shot') AS avg_xg,
(SELECT COUNT(*) FROM set_piece_clusters) AS clusters,
(SELECT COUNT(*) FROM model_registry) AS models,
(SELECT COUNT(*) FROM xt_surface) AS xt_surface_cells; xt_rows | xp_rows | xg_rows | avg_xg | clusters | models | xt_surface_cells
----------+-----------+---------+--------+----------+--------+------------------
5375085 | 3387760 | 88023 | 0.1112 | 24 | 4 | 192
$ gh run list --limit 5
STATUS TITLE WORKFLOW BRANCH ELAPSED
✓ fix: dual-perspective audit — football accuracy + … CI / CD main 1m31s
✓ feat: audit fixes — coverage threshold, new tests … CI / CD main 1m44s
✓ fix: correct ml_dag task IDs in DAG tests + LICENSE CI / CD main 1m38s
✓ docs: add Live Pipeline Output section to README CI / CD main 1m29s
✓ test: add DAG integrity tests (load, task IDs, …) CI / CD main 1m35s
All five jobs pass — lint (black · isort · flake8), unit tests (46+ tests across 7 files including xG model tests; DAG tests skip gracefully without Airflow), and dbt compile check.
xforge/
├── .devcontainer/
│ └── devcontainer.json # Codespaces: docker up + xP auto-resume on restart
├── .github/
│ └── workflows/deploy.yml # lint → test → dbt-check → deploy (EC2)
├── config/
│ ├── grafana/ # Provisioned dashboards & Prometheus datasource
│ └── superset_config.py # Superset secret key & DB URI
├── dags/
│ ├── ingestion_dag.py # Daily ETL — ingest → dbt → xT → superset
│ ├── ml_dag.py # Weekly — xP + K-Means parallel → dbt marts
│ └── matchday_dag.py # On-demand — ingest → PDF → XML → email
├── dbt_project/
│ └── models/
│ ├── staging/ # stg_events, stg_passes, stg_shots (3 models)
│ └── marts/ # player_metrics, team_summary,
│ # match_summary, competition_leaderboard
├── scripts/
│ ├── init/ # 01_schema.sql — tables, partitions, indexes
│ ├── massive_ingestion.py # Incremental StatsBomb loader (upsert, 50k chunks)
│ ├── xt_model.py # Value-iteration xT surface builder
│ ├── predictive_models.py # XGBoost xP — sample train + chunked prediction
│ ├── xg_model.py # XGBoost xG — shot goal probability + calibration
│ ├── tactical_models.py # K-Means set-piece clustering + press detection
│ ├── report_generator.py # 5-page PDF via mplsoccer + matplotlib
│ ├── xml_generator.py # SportsCode/Hudl XML — top-25 xT events
│ ├── setup_superset.py # Autonomous Superset bootstrap — 7 charts + dashboard
│ └── superset_init.py # Bootstraps saved queries on first run
├── tests/ # pytest suite — unit + schema validation
├── docker-compose.yml # 8 services: Airflow (3), Postgres, Superset,
│ # Grafana, pgAdmin, Redis
├── Dockerfile.airflow # Custom image: Python deps + dbt + mplsoccer
├── Makefile # Developer shortcuts (see below)
├── requirements.txt
└── .env.example # Template — copy to .env before first run
- Docker ≥ 24 and Docker Compose v2
- 4 GB RAM minimum (8 GB recommended)
- Git
git clone https://github.com/bbasaranemir/xforge.git
cd xforge
cp .env.example .envGenerate a Fernet key for Airflow and paste it into .env:
python3 -c "from cryptography.fernet import Fernet; print(Fernet.generate_key().decode())"make up # build images + start 8 containers
make status # verify all services are healthymake ingest # unpause + trigger ingestion_pipeline DAG
make logs # tail scheduler logsmake report MATCH_ID=3942349
# → reports/match_3942349.pdf (5 pages)
# → reports/match_3942349_sportscode.xml (25 events)| Service | URL | Default credentials |
|---|---|---|
| Airflow | http://localhost:8080 | see .env → AIRFLOW_USER / AIRFLOW_PASSWORD |
| Superset | http://localhost:8088 | see .env → SUPERSET_USER / SUPERSET_PASSWORD |
| Grafana | http://localhost:3000 | admin / admin |
| pgAdmin | http://localhost:5050 | see .env → PGADMIN_EMAIL / PGADMIN_PASSWORD |
Click Code → Codespaces → New. All services start automatically via .devcontainer; forwarded ports are pre-configured.
Every push to main runs:
lint (black · isort · flake8)
└─► unit tests (pytest + coverage → Codecov)
└─► dbt compile check
└─► deploy to EC2 (requires secrets)
| Secret | Purpose |
|---|---|
EC2_HOST |
EC2 public IP or DNS |
EC2_USER |
SSH username |
EC2_SSH_KEY |
Private key (PEM contents) |
The deploy job is non-blocking (continue-on-error: true) — CI stays green in environments without EC2 configured.
dim_competitions ─┐
dim_seasons ──────┤
dim_matches ──────┤
dim_players ──────┼──► fact_events (PARTITION BY LIST competition_id, 40+ parts)
dim_teams ────────┘ │
├──► xt_surface (192 cells, 16×12 grid)
├──► model_registry (AUC, log-loss, artifact path)
├──► set_piece_clusters (24 centroids)
├──► press_events (trigger sequences)
│
└──► analytics_marts.*
├── mart_player_metrics (total_xg · avg_xg · finishing_quality)
├── mart_team_summary (avg_xp — NULL-aware)
├── mart_match_summary
└── mart_competition_leaderboard (xt_per_match · xt_per_match_rank)
StatsBomb Open Data — used under the StatsBomb Open Data Licence. This project is not affiliated with or endorsed by StatsBomb.
MIT