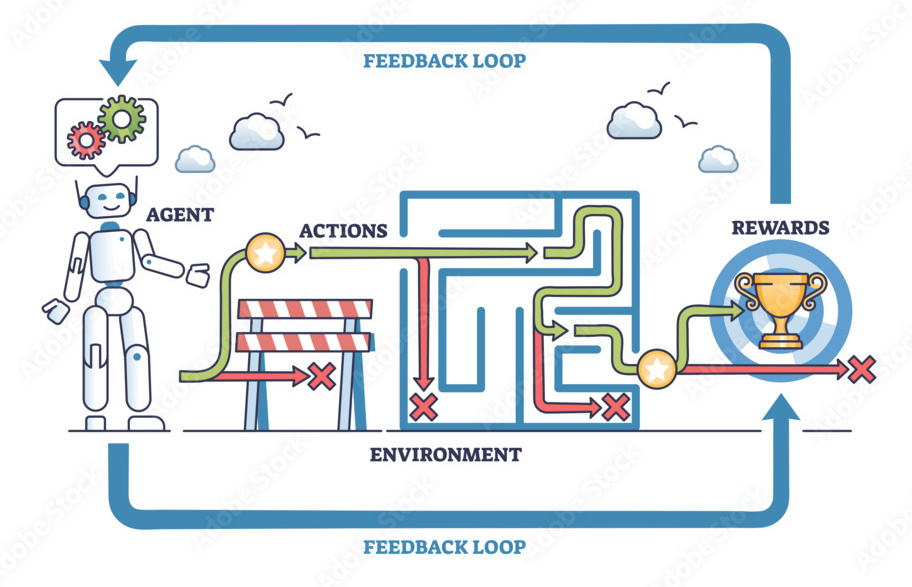
A comprehensive collection of Reinforcement Learning implementations from the Deep RL Course, featuring 12+ trained agents across diverse environments. This repository demonstrates mastery over various RL algorithms including Deep Q-Networks (DQN) , Proximal Policy Optimization (PPO) , Advantage Actor-Critic (A2C) , REINFORCE, and Q-Learning across platforms like Unity ML-Agents, Gymnasium, Stable-Baselines3, and VizDoom.
| 🎯 Repository Highlights | 🏗️ Repository Structure |
| 🔃 Applied RL Projects | 🏆 Certification Results |
| ⚙️ Technical Stack | 🚀 Getting Started |
| 📊 Performance Metrics | 🤝 Contribution |
- ✅ 10/12 Units Passed in Deep RL Course (80%+ completion)
- 🧠 6+ RL Algorithms: PPO, DQN, A2C, REINFORCE, Q-Learning
- 🎮 12+ Environments: Unity ML-Agents, Gymnasium, Atari, VizDoom, PandaGym
- 🏆 Course Certification: Deep RL Course Certificate
- 🎥 Interactive Demos: Video replays embedded in project explanations
📁 Reinforcement-Learning-Practice/
│
├── 📁 # 1️⃣ HUGGY UNITY ML (Bonus Unit)
├── 1_HuggyUnityML/
│ └── bonus_unit1.ipynb → Training Huggy the Dog with PPO
│
├── 📁 # 2️⃣ LUNAR LANDER (Unit 1)
├── 2_LunarLanderBaseline3/
│ └── unit1.ipynb → PPO with Stable-Baselines3
│
├── 📁 # 3️⃣ TABULAR RL (Unit 2)
├── 3_Taxi&FrozenLakeGymnasium/
│ └── unit2.ipynb → Q-Learning from scratch
│
├── 📁 # 4️⃣ ATARI SPACE INVADERS (Unit 3)
├── 4_AtariSpaceInvadersBaseline3/
│ └── unit3.ipynb → DQN for Space Invaders
│
├── 📁 # 5️⃣ POLICY GRADIENTS (Unit 4)
├── 5_Cartpole&PixelcopterPytorch/
│ └── unit4.ipynb → REINFORCE from scratch
│
├── 📁 # 6️⃣ UNITY ADVANCED (Unit 5)
├── 6_Pyramid&SnowballTargetUnityML/
│ └── unit5.ipynb → Pyramids & Snowball with PPO
│
├── 📁 # 7️⃣ ROBOTICS RL (Unit 6)
├── 7_AdvantageAutoCriticPandaGym/
│ └── unit6.ipynb → A2C for Panda Robots
│
├── 📁 # 8️⃣ VIZDOOM AGENT (Unit 8 Part II)
├── 8_DoomAgentVizdoom/
│ └──unit8_part2.ipynb → VizDoom Environment and Agent for Doom Game Agent
│
├── 📁 # 🎥 DEMONSTRATION MEDIA
├── Demo/
│ └── 📁 gif/
│ ├── replay1.gif → Huggy Unity Training
│ ├── replay2.gif → Lunar Lander Landing
│ ├── replay3.1.gif → Taxi-v3 Optimal Path
│ ├── replay3.2.gif → FrozenLake Navigation
│ ├── replay4.gif → Space Invaders Gameplay
│ ├── replay5.1.gif → Cartpole Balance
│ ├── replay5.2.gif → PixelCopter Flight
│ ├── replay6.1.gif → Pyramids Completion
│ ├── replay6.2.gif → Snowball Target Hit
│ ├── replay7.1.gif → Panda Pick & Place
│ ├── replay7.2.gif → Panda Reach Dense
│ └── replay8.gif → VizDoom Doom Agent
│ └── 📁 img/
│ └── display.png → RL Workflow Display
│
└── README.md → You are here!
Hugging Face Repo: KraTUZen/ppo-Huggy
Training the adorable dog "Huggy" to fetch sticks in Unity ML-Agents environment using PPO. This project introduces Unity ML-Agents toolkit and demonstrates 3D environment training.

🦴 Huggy learning to fetch sticks (Best Score: 3.827)
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| PPO | Unity ML-Agents | ML-Agents-Huggy | 3.0 | 3.827 |
Hugging Face Repo: KraTUZen/ppo-LunarLander-v2
Mastering the Lunar Lander environment using Proximal Policy Optimization (PPO) with Stable-Baselines3. The agent learns to land safely between the flags with precision control.

🌑 lunar landing (Score: 245.02 / 200 required)
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| PPO | Stable-Baselines3 | LunarLander-v2 | 200 | 245.02 |
Hugging Face Repos: KraTUZen/q-Taxi-v3, KraTUZen/q-FrozenLake-v1-no-slippery
Classic tabular Q-Learning implementations from scratch. Taxi-v3 involves passenger pickup/dropoff, while FrozenLake demonstrates navigation in grid worlds.

🚕 Taxi-v3 (Score: 4.85) |

❄️ FrozenLake (Score: 1.0) |
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| Q-Learning | Gymnasium | Taxi-v3 | 4.0 | 4.85 |
| Q-Learning | Gymnasium | FrozenLake-v1 | 0.5 | 1.0 |
Hugging Face Repo: KraTUZen/dqn-SpaceInvadersNoFrameskip-v4
Deep Q-Network (DQN) for the classic Atari game Space Invaders. Features CNN-based feature extraction from raw pixels, experience replay, and target networks.
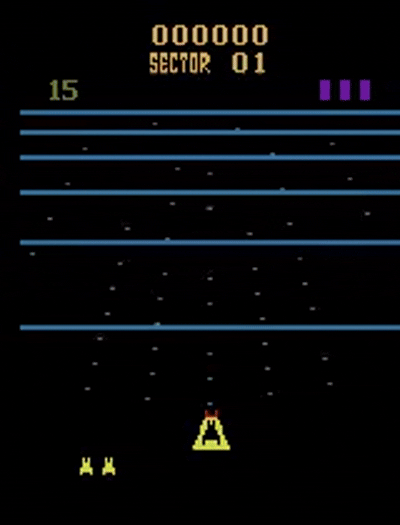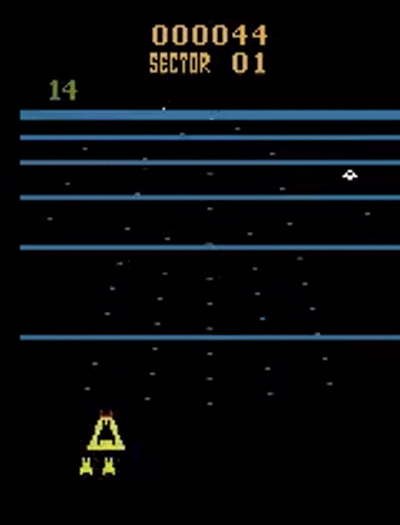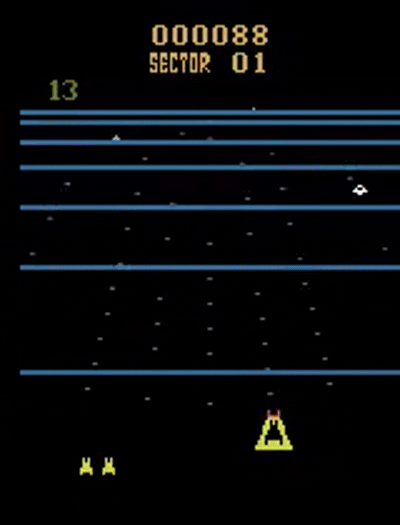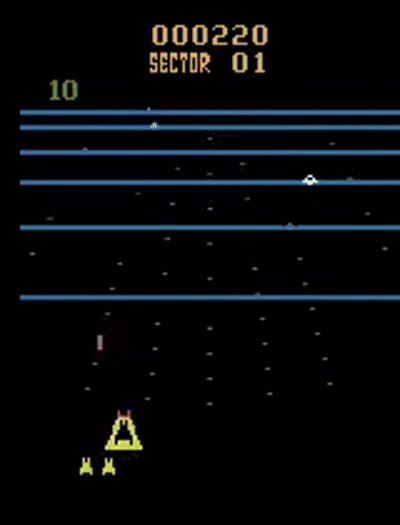
☄ Space Invaders Gameplay (Score: 451.47 / 200 required)
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| DQN | Stable-Baselines3 | SpaceInvadersNoFrameskip-v4 | 200 | 451.47 |
Hugging Face Repos: KraTUZen/Reinforce-CartPole-v1, KraTUZen/Reinforce-PixelCopter
REINFORCE algorithm implementations from scratch using PyTorch. CartPole demonstrates policy gradients simply, while PixelCopter handles vision-based continuous control.

⚖️ CartPole (Score: 500) |

🚁 PixelCopter (Score: 12.03) |
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| REINFORCE | PyTorch | CartPole-v1 | 350 | 500 |
| REINFORCE | PyTorch | PixelCopter-PLE-v0 | 5 | 12.03 |
Hugging Face Repos: KraTUZen/ppo-PyramidsTraining, KraTUZen/ppo-SnowballTarget
Advanced Unity ML-Agents environments solved with PPO. Pyramids requires building structures, while Snowball Target involves hitting moving targets.

🔺 Pyramids (Score: 1.38) |

🎯 Snowball Target (Score: 3.27) |
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| PPO | Unity ML-Agents | Pyramids | -100 | 1.38 |
| PPO | Unity ML-Agents | SnowballTarget | -100 | 3.27 |
Hugging Face Repos: KraTUZen/a2c-PandaReachDense-v3, KraTUZen/a2c-PandaPickAndPlace-v3
Robotics manipulation with Franka Emika Panda robot arm using A2C. Tasks include reaching targets and pick-and-place operations.

🎍 Panda Pick & Place (Score: 2.5) |

🦾 Panda Reach Dense (Score: 2.5) |
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| A2C | PandaGym | PandaPickAndPlace-v3 | -3.5 | 2.5 |
| A2C | PandaGym | PandaReachDense-v3 | -3.5 | 2.5 |
Hugging Face Repo: KraTUZen/Vizdoom-Doom-Agent
First-person shooter agent trained in VizDoom to gather health packs and defeating enemies if encountered. Demonstrates RL in partially observable 3D environments.

🔫 VizDoom Doom Agent (Score: 5.34 / 5 required)
| Algorithm | Framework | Environment | Min Required | Best Result |
|---|---|---|---|---|
| PPO | VizDoom | Vizdoom-Doom-Agent | 5 | 5.34 |
| Status | Unit | Environment | Min Required | Best Result | Best Model ID |
|---|---|---|---|---|---|
| ✅ | Bonus Unit 1 | ML-Agents-Huggy | 3.0 | 3.827 | ppo-Huggy |
| ✅ | Unit 1 | LunarLander-v2 | 200 | 245.02 | ppo-LunarLander-v2 |
| ✅ | Unit 2 | Taxi-v3 | 4.0 | 4.85 | q-Taxi-v3 |
| ✅ | Unit 2 | FrozenLake-v1 | 0.5 | 1.0 | q-FrozenLake-v1-no-slippery |
| ✅ | Unit 3 | SpaceInvadersNoFrameskip-v4 | 200 | 451.47 | dqn-SpaceInvadersNoFrameskip-v4 |
| ✅ | Unit 4 | CartPole-v1 | 350 | 500 | Reinforce-CartPole-v1 |
| ✅ | Unit 4 | PixelCopter-PLE-v0 | 5 | 12.03 | Reinforce-PixelCopter |
| ✅ | Unit 5 | ML-Agents-SnowballTarget | -100 | 3.27 | ppo-SnowballTarget |
| ✅ | Unit 5 | ML-Agents-Pyramids | -100 | 1.38 | ppo-PyramidsTraining |
| ✅ | Unit 6 | PandaReachDense-v3 | -3.5 | 2.5 | a2c-PandaReachDense-v3 |
| ✅ | Unit 6 | PandaPickAndPlace-v3 | -3.5 | 2.5 | a2c-PandaPickAndPlace-v3 |
| ❌ | Unit 7 | ML-Agents-SoccerTwos | -100 | -1000 | Skipped (Corrupted) |
| ❌ | Unit 8 PI | LunarLander-v2 | -500 | -1000 | Skipped (Similar to Unit 1) |
| ✅ | Unit 8 PII | Doom-Health-Gathering-Supreme | 5 | 5.34 | Vizdoom-Doom-Agent |

✅ Achieved 80%+ completion requirement (10/12 units passed)
| Category | Technologies |
|---|---|
| RL Libraries | Stable-Baselines3, HuggingFace Hub 🤗 |
| Deep Learning | PyTorch, TensorBoard |
| Environments | Gymnasium, Unity ML-Agents, VizDoom, PandaGym, PyBullet, Atari-Py |
| Algorithms | PPO, DQN, A2C, REINFORCE, Q-Learning |
# Create environment
conda env create -f environment.yml
# Activate
conda activate rl-practice
# Verify installation
python -c "import gymnasium; print('✅ Gymnasium OK')"# Create virtual environment
python -m venv venv
# Activate (Windows)
venv\Scripts\activate
# Activate (Linux/Mac)
source venv/bin/activate
# Install dependencies
pip install -r requirements.txt# Navigate to project folder
cd "1_HuggyUnityML"
# Launch Jupyter
jupyter notebook bonus_unit1.ipynb| Environment | Algorithm | Min Required | Best Score | Improvement |
|---|---|---|---|---|
| Huggy | PPO | 3.0 | 3.827 | +27.6% |
| LunarLander-v2 | PPO | 200 | 245.02 | +22.5% |
| Taxi-v3 | Q-Learning | 4.0 | 4.85 | +21.3% |
| FrozenLake-v1 | Q-Learning | 0.5 | 1.0 | +100% |
| SpaceInvaders | DQN | 200 | 451.47 | +125.7% |
| CartPole-v1 | REINFORCE | 350 | 500 | +42.9% |
| PixelCopter | REINFORCE | 5 | 12.03 | +140.6% |
| SnowballTarget | PPO | -100 | 3.27 | +103.3%* |
| Pyramids | PPO | -100 | 1.38 | +101.4%* |
| PandaReach | A2C | -3.5 | 2.5 | +171.43%* |
| PandaPickAndPlace | A2C | -3.5 | 2.5 | +171.43%* |
| VizDoomAgent | PPO | 5 | 5.34 | +6.8% |
*Relative improvement from negative baseline
Contributions are welcome! Whether it's new algorithms, environments, or improvements:
- 🍴 Fork the repository
- 🌿 Create a feature branch (
git checkout -b feature/NewAlgorithm) - 💾 Commit changes (
git commit -m 'Add NewAlgorithm') - 📤 Push to branch (
git push origin feature/NewAlgorithm) - 🔃 Open a Pull Request